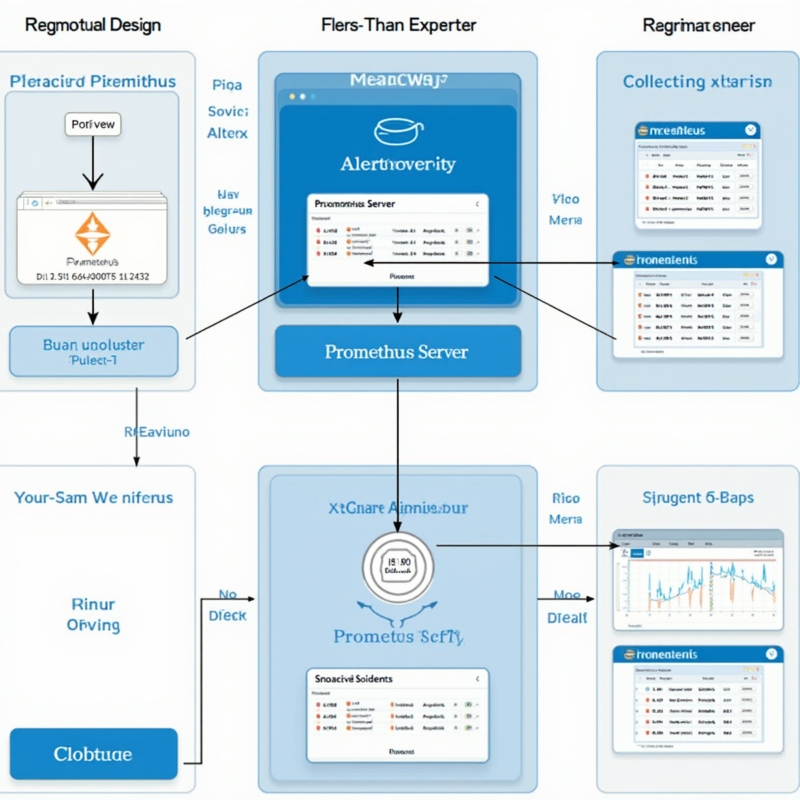

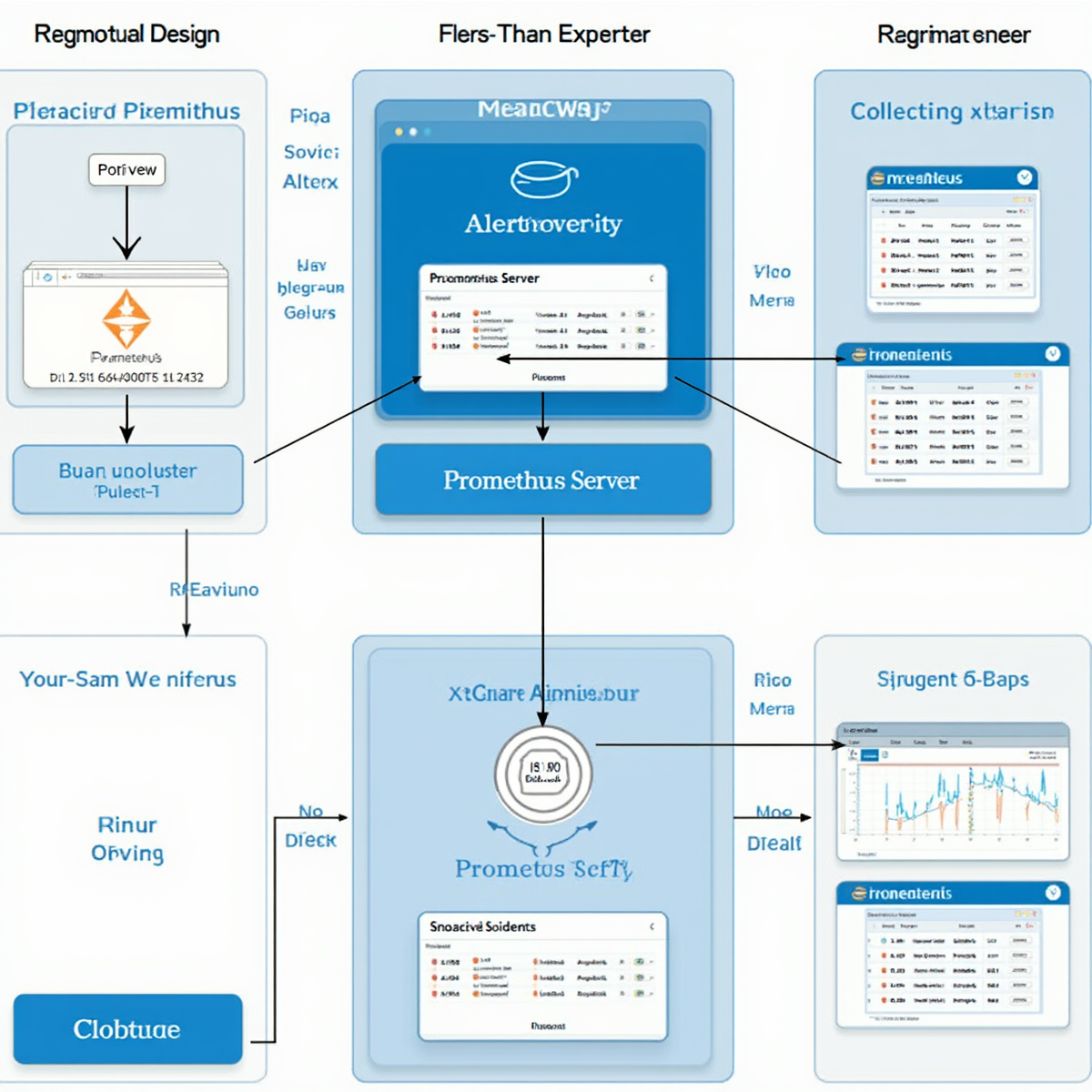
Prometheus 监控系统详细使用教程
核心概念
Prometheus 是一个开源的系统监控和警报工具包,最初由 SoundCloud 于 2012 年开发,2016 年加入 Cloud Native Computing Foundation (CNCF) 成为第二个孵化项目。其核心设计理念包括:
- 多维数据模型:以指标名称和键值对(labels)来标识时间序列数据,支持灵活的查询和分析。
- Pull 机制:通过 HTTP 拉取目标服务的指标数据,而非被动接收推送。
- 无依赖存储:本地时间序列存储,不依赖外部存储系统。
- 强大的查询语言:PromQL 提供灵活的查询能力,支持聚合、过滤和数学运算。
- 告警机制:内置 Alertmanager 负责告警的接收、分组和路由。
安装配置
方法一:二进制文件安装
# 下载 Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.47.0/prometheus-2.47.0.linux-amd64.tar.gz
tar xvfz prometheus-2.47.0.linux-amd64.tar.gz
cd prometheus-2.47.0.linux-amd64/
启动服务
./prometheus --config.file=prometheus.yml
方法二:Docker 安装
docker run -d \
--name prometheus \
-p 9090:9090 \
-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
方法三:Kubernetes 安装(推荐)
使用 Helm Chart 安装:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/kube-prometheus-stack
prometheus.yml 配置示例
“`yaml
global:
scrape_interval: 15s # 全局抓取间隔
evaluation_interval: 15s # 规则评估间隔
external_labels:
monitor: ‘my-project’
警报管理器配置
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
目标抓取配置
scrape_configs:
# Prometheus 自身监控
- job_name: ‘prometheus’
static_configs:
- targets: [‘localhost:9090’]
# Kubernetes 节点监控
- job_name: ‘kubernetes-nodes’
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
# Kubernetes Pod 监控
- job_name: ‘kubernetes-pods’
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# 自定义应用监控
- job_name: ‘my-application’
static_configs:
- targets: [‘192.168.1.100:8080’]
metrics_path: ‘/actuator/prometheus’
relabel_configs:
- source_labels: [__address__]
target_label: instance
regex: ‘(.+):(.+)’
replacement: ‘${1}’
# Node Exporter 系统监控
- job_name: ‘node’
static_configs:
- targets: [‘node-exporter:9100’]
告警规则
Prometheus 通过规则文件定义告警逻辑:
yaml
groups:
- name: application_alerts
interval: 30s
rules:
# CPU 使用率过高告警
- alert: HighCPUUsage
expr: 100 – (avg by(instance) (irate(node_cpu_seconds_total{mode=”idle”}[5m])) * 100) > 80
for: 5m
labels:
severity: warning
annotations:
summary: “高 CPU 使用率告警”
description: “{{ $labels.instance }} CPU 使用率超过 80%”
# 内存使用率过高告警
- alert: HighMemoryUsage
expr: (1 – (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85
for: 5m
labels:
severity: critical
annotations:
summary: “高内存使用率告警”
description: “{{ $labels.instance }} 内存使用率超过 85%”
# 服务不可用告警
- alert: ServiceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: “服务不可用”
description: “{{ $labels.instance }} 服务已停止响应”
# 磁盘空间不足告警
- alert: LowDiskSpace
expr: (node_filesystem_avail_bytes{fstype!=”tmpfs”} / node_filesystem_size_bytes{fstype!=”tmpfs”}) * 100 < 10 for: 10m labels: severity: warning annotations: summary: "磁盘空间不足" description: "{{ $labels.instance }} 磁盘剩余空间不足 10%"
Grafana 集成
Grafana 是 Prometheus 的最佳可视化伴侣,集成步骤如下:
1. 添加 Prometheus 数据源
在 Grafana 中配置数据源:
- 访问 Grafana Web 界面(默认端口 3000)
- 进入 Configuration → Data Sources
- 点击 "Add data source",选择 Prometheus
- 设置 Server URL: `http://prometheus:9090`
- 点击 "Save & Test" 确认连接成功
2. 导入预置仪表板
Prometheus 官方提供多个预置仪表板:
- Kubernetes 监控仪表板(ID: 315)
- Node Exporter 全功能仪表板(ID: 1860)
- 自定义业务监控仪表板
3. 创建自定义查询
使用 PromQL 构建复杂查询:
promql
5 分钟内请求错误率超过 5%
sum(rate(http_requests_total{status=~”5..”}[5m])) / sum(rate(http_requests_total[5m])) * 100 > 5
每秒平均响应时间
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))
“`
实际应用场景
场景一:微服务监控
在 Kubernetes 集群中部署 Prometheus,通过 Service Discovery 自动发现所有微服务实例,监控每个服务的 QPS、延迟、错误率等关键指标。
场景二:基础设施监控
部署 Node Exporter 到所有服务器节点,收集 CPU、内存、磁盘、网络等系统级指标,设置告警规则实现故障预警。
场景三:业务指标监控
通过 Exporter 或自定义代码暴露业务指标,如订单量、用户活跃度、支付成功率等,结合 Grafana 实现业务数据可视化。
场景四:日志聚合与分析
配合 Loki 和 Promtail 实现日志与指标的关联分析,快速定位故障根因。
最佳实践建议
- 合理的指标采集频率:避免过高频率导致性能开销,一般 15-30 秒为宜。
- 标签优化:避免高基数标签导致存储膨胀,合理控制标签值数量。
- 告警降噪:通过分组、抑制规则减少告警风暴,确保告警有效性。
- 数据保留策略:根据业务需求配置合适的数据保留期限,平衡存储成本。
- 定期备份:定期备份 Prometheus 数据目录,防止数据丢失。
—
结语:Prometheus 以其简洁的设计、强大的查询能力和活跃的生态系统,成为云原生时代的标准监控解决方案。掌握 Prometheus 的核心概念和使用方法,将大大提升你的系统可观测性和运维效率。









暂无评论内容