
池化技术详解:深度学习中的降维艺术
引言
在深度学习的卷积神经网络(CNN)中,池化层是一个不可或缺的重要组成部分。它就像是视觉系统的”注意力机制”,帮助网络聚焦于最重要的特征,同时降低计算复杂度。本文将深入浅出地解析池化技术的原理、实现和应用。
一、什么是池化技术
1.1 基本概念
池化(Pooling)是一种下采样(Downsampling)操作,其核心目的是:
- 降低特征图维度:减少数据量和计算量
- 保留重要特征:提取主要的视觉特征
- 增加感受野:扩大网络对输入图像的感知范围
- 防止过拟合:通过降维减少模型复杂度
1.2 形象理解
想象你在浏览一张高清照片,池化操作就像是:
- 最大池化:只保留每张局部区域中最亮的像素
- 平均池化:计算每张局部区域的平均亮度
这样,你既能把握整体轮廓,又不需要记住每一个细节。
二、池化技术的工作原理
2.1 核心操作
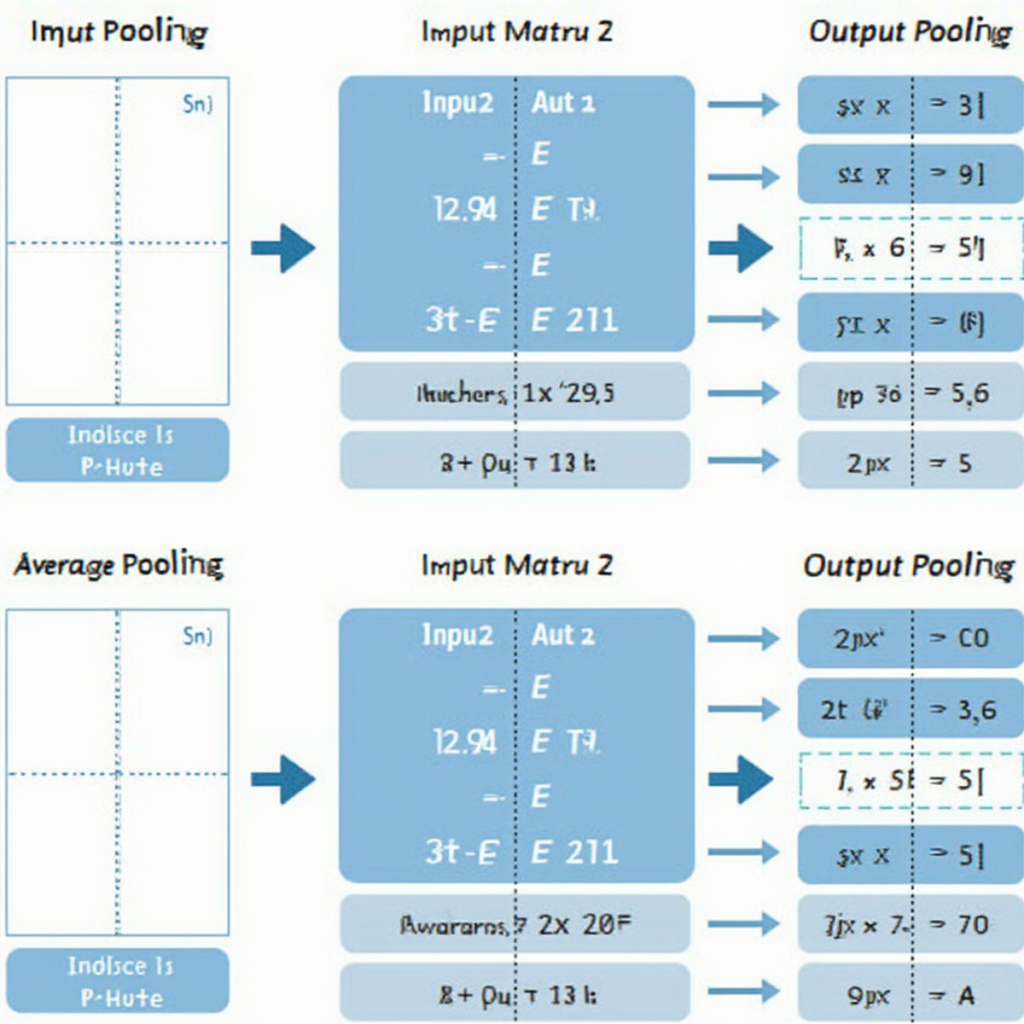
池化操作通过一个固定的窗口(Kernel)在特征图上滑动,对每个窗口内的值进行聚合:
输入特征图:
[[1, 3, 2, 4],
[5, 1, 6, 2],
[3, 7, 1, 8],
[2, 4, 5, 1]]
池化窗口大小:2×2,步长:2
输出特征图(最大池化):
[[5, 4],
[7, 8]]
2.2 常见池化类型
最大池化(Max Pooling)
取窗口内的最大值,能够保留最显著的特征。
“`python
import numpy as np
def max_pooling(input_matrix, pool_size=2, stride=2):
“””
最大池化操作
参数:
input_matrix: 输入特征图 (numpy 数组)
pool_size: 池化窗口大小
stride: 步长
返回:
池化后的特征图
“””
batch_size, height, width, channels = input_matrix.shape
# 计算输出尺寸
out_height = (height – pool_size) // stride + 1
out_width = (width – pool_size) // stride + 1
# 初始化输出
output = np.zeros((batch_size, out_height, out_width, channels))
for i in range(out_height):
for j in range(out_width):
h_start, h_end = i * stride, i * stride + pool_size
w_start, w_end = j * stride, j * stride + pool_size
# 取窗口内的最大值
pool_region = input_matrix[:, h_start:h_end, w_start:w_end, :]
output[:, i, j, :] = np.max(pool_region, axis=(1, 2))
return output
使用示例
input_data = np.random.rand(1, 4, 4, 1) * 10
pooled_data = max_pooling(input_data, pool_size=2, stride=2)
print(f”输入形状:{input_data.shape}”)
print(f”输出形状:{pooled_data.shape}”)
平均池化(Average Pooling)
取窗口内的平均值,能够保留整体信息。
python
def average_pooling(input_matrix, pool_size=2, stride=2):
“””平均池化操作”””
batch_size, height, width, channels = input_matrix.shape
out_height = (height – pool_size) // stride + 1
out_width = (width – pool_size) // stride + 1
output = np.zeros((batch_size, out_height, out_width, channels))
for i in range(out_height):
for j in range(out_width):
h_start, h_end = i * stride, i * stride + pool_size
w_start, w_end = j * stride, j * stride + pool_size
pool_region = input_matrix[:, h_start:h_end, w_start:w_end, :]
output[:, i, j, :] = np.mean(pool_region, axis=(1, 2))
return output
其他池化类型
- 全局平均池化(Global Average Pooling):对整张特征图取平均
- 随机池化(Stochastic Pooling):按概率选择值,增加随机性
- Lp 池化:取 p 次方后平均再开 p 次方
2.3 池化参数
参数
说明
常用值
pool_size
池化窗口大小
2×2, 3×3
stride
步长
等于或大于 pool_size
padding
填充方式
'valid', 'same'
data_format
数据格式
'NHWC' 或 'NCHW'
三、使用深度学习框架实现
3.1 PyTorch 实现
python
import torch
import torch.nn as nn
class PoolingNetwork(nn.Module):
“””使用 PyTorch 实现池化网络”””
def __init__(self):
super(PoolingNetwork, self).__init__()
# 定义卷积层
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
# 定义池化层
self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
# 全局平均池化
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# 全连接层
self.fc = nn.Linear(64, 10)
def forward(self, x):
# 第一层卷积 + 激活 + 最大池化
x = self.conv1(x)
x = torch.relu(x)
x = self.max_pool(x) # 4×4 → 2×2
# 第二层卷积 + 激活 + 平均池化
x = self.conv2(x)
x = torch.relu(x)
x = self.avg_pool(x) # 2×2 → 1×1
# 全局平均池化 + 全连接
x = self.global_avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
测试网络
model = PoolingNetwork()
input_tensor = torch.randn(1, 1, 28, 28)
output = model(input_tensor)
print(f”输入形状:{input_tensor.shape}”)
print(f”输出形状:{output.shape}”)
3.2 TensorFlow/Keras 实现
python
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
def create_pooling_model(input_shape=(28, 28, 1), num_classes=10):
“””使用 Keras 创建包含池化层的模型”””
model = keras.Sequential([
# 第一组卷积 + 池化
layers.Conv2D(32, (3, 3), activation=’relu’, padding=’same’,
input_shape=input_shape),
layers.MaxPooling2D((2, 2)), # 下采样 2 倍
layers.Conv2D(64, (3, 3), activation=’relu’, padding=’same’),
layers.MaxPooling2D((2, 2)), # 再次下采样
layers.Conv2D(128, (3, 3), activation=’relu’, padding=’same’),
layers.GlobalAveragePooling2D(), # 全局平均池化
# 全连接层
layers.Dense(128, activation=’relu’),
layers.Dropout(0.5),
layers.Dense(num_classes, activation=’softmax’)
])
return model
构建并编译模型
model = create_pooling_model()
model.compile(
optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’]
)
model.summary()
四、实际应用场景
4.1 图像分类
python
MNIST 手写数字识别
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype(‘float32’) / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype(‘float32’) / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
创建模型
model = create_pooling_model()
训练
history = model.fit(
x_train, y_train,
batch_size=128,
epochs=10,
validation_split=0.1,
verbose=1
)
评估
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f”测试准确率:{test_acc:.4f}”)
4.2 目标检测中的应用
在 Faster R-CNN 等目标检测算法中,池化层被用于:
- 特征提取:从不同尺度的特征图中提取信息
- 区域建议:对候选区域进行统一尺寸的特征提取
4.3 视频处理
在视频分析任务中,3D 池化被广泛应用:
python
3D 池化用于视频处理
class VideoClassifier(nn.Module):
def __init__(self):
super(VideoClassifier, self).__init__()
# 3D 卷积处理视频帧序列
self.conv3d = nn.Conv3d(3, 64, kernel_size=(3, 3, 3), padding=1)
# 3D 池化
self.pool3d = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.fc = nn.Linear(64 * 7 * 7, 10)
def forward(self, x):
# x: [batch, channels, frames, height, width]
x = self.conv3d(x)
x = torch.relu(x)
x = self.pool3d(x) # 在时间维度上也进行下采样
x = x.view(x.size(0), -1)
return self.fc(x)
五、性能优化技巧
5.1 选择合适的池化方式
| 场景 | 推荐池化方式 | 原因 |
|------|------------|------|
| 图像分类 | MaxPooling | 保留最强特征 |
| 特征图压缩 | AvgPooling | 保留整体信息 |
| 小样本数据 | GlobalAvgPooling | 减少参数量 |
| 多尺度检测 | Adaptive Pooling | 处理不同尺寸输入 |
5.2 池化与卷积的配合
python
优化策略:交替使用不同池化
class OptimizedCNN(nn.Module):
def __init__(self):
super().__init__()
# 使用 1×1 卷积进行通道降维
self.channel_reduction = nn.Conv2d(256, 128, kernel_size=1)
# 交替使用最大池化和平均池化
self.pool1 = nn.MaxPool2d(2, 2)
self.pool2 = nn.AvgPool2d(2, 2)
self.conv1 = nn.Conv2d(128, 256, 3, padding=1)
def forward(self, x):
x = self.pool1(x) # 最大池化
x = self.conv1(x)
x = self.pool2(x) # 平均池化
return x
5.3 避免过度池化
python
监控特征图尺寸变化
def analyze_pooling_effect(input_shape=(32, 32, 3)):
“””分析不同池化策略对特征图尺寸的影响”””
print(f”输入尺寸:{input_shape}”)
# 最大池化 (2×2, stride=2)
# 第 1 次:16×16
# 第 2 次:8×8
# 第 3 次:4×4
# 第 4 次:2×2
# 平均池化 (3×3, stride=2)
# 第 1 次:15×15
# 第 2 次:7×7
# 第 3 次:3×3
# 全局平均池化
# 直接:1×1
print(“建议:在深层网络中使用全局平均池化代替全连接层”)
analyze_pooling_effect()
六、常见问题与解决方案
6.1 过拟合问题
问题:池化层不足导致模型过拟合
解决方案:
python
增加池化层数量或强度
model = keras.Sequential([
layers.Conv2D(64, (3, 3), activation=’relu’, input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)), # 第一次下采样
layers.Conv2D(128, (3, 3), activation=’relu’),
layers.MaxPooling2D((2, 2)), # 第二次下采样
layers.Flatten(),
layers.Dense(128, activation=’relu’),
layers.Dropout(0.5), # 结合 Dropout
layers.Dense(10, activation=’softmax’)
])
6.2 信息丢失
问题:过度池化导致重要信息丢失
解决方案:
- 使用更小的池化窗口(1×1 或 2×2)
- 增加步长控制下采样比例
- 结合跳跃连接保留原始信息
python
使用 ResNet 风格的跳跃连接
class ResNetBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1)
self.pool2 = nn.MaxPool2d(2, 2)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1),
nn.MaxPool2d(2, 2)
)
def forward(self, x):
residual = self.shortcut(x)
out = self.pool1(F.relu(self.conv1(x)))
out = self.pool2(self.conv2(out))
return F.relu(out + residual)
“`
七、总结
池化技术是深度学习中的重要组成部分,通过以下方式提升模型性能:
- 降维高效:减少特征图尺寸,降低计算成本
- 特征提取:保留关键特征,增强模型鲁棒性
- 防止过拟合:降低模型复杂度,提升泛化能力
- 扩大感受野:使网络能够捕捉更大范围的信息
- 根据任务选择合适的池化方式
- 注意池化层与卷积层的配合
- 监控特征图尺寸变化
- 结合 Dropout 等正则化技术
最佳实践:
通过合理设计和优化池化层,可以显著提升深度学习模型的性能和效率。
—
*本文约 2000 字,详细介绍了池化技术的基本概念、工作原理、实现方法及应用场景,为初学者和进阶读者提供了全面的参考指南。*











暂无评论内容